Posing 3D characters is a fundamental task in computer graphics.
However, existing paradigms, ranging from traditional auto-rigging to recent pose-conditioned generative
models, frequently struggle with inaccurate skinning weights, fixed mesh topologies, and poor pose
conformance. These challenges have become particularly pronounced with the recent explosion of
AI-generated 3D assets, which often exhibit flawed structures and fused geometry.
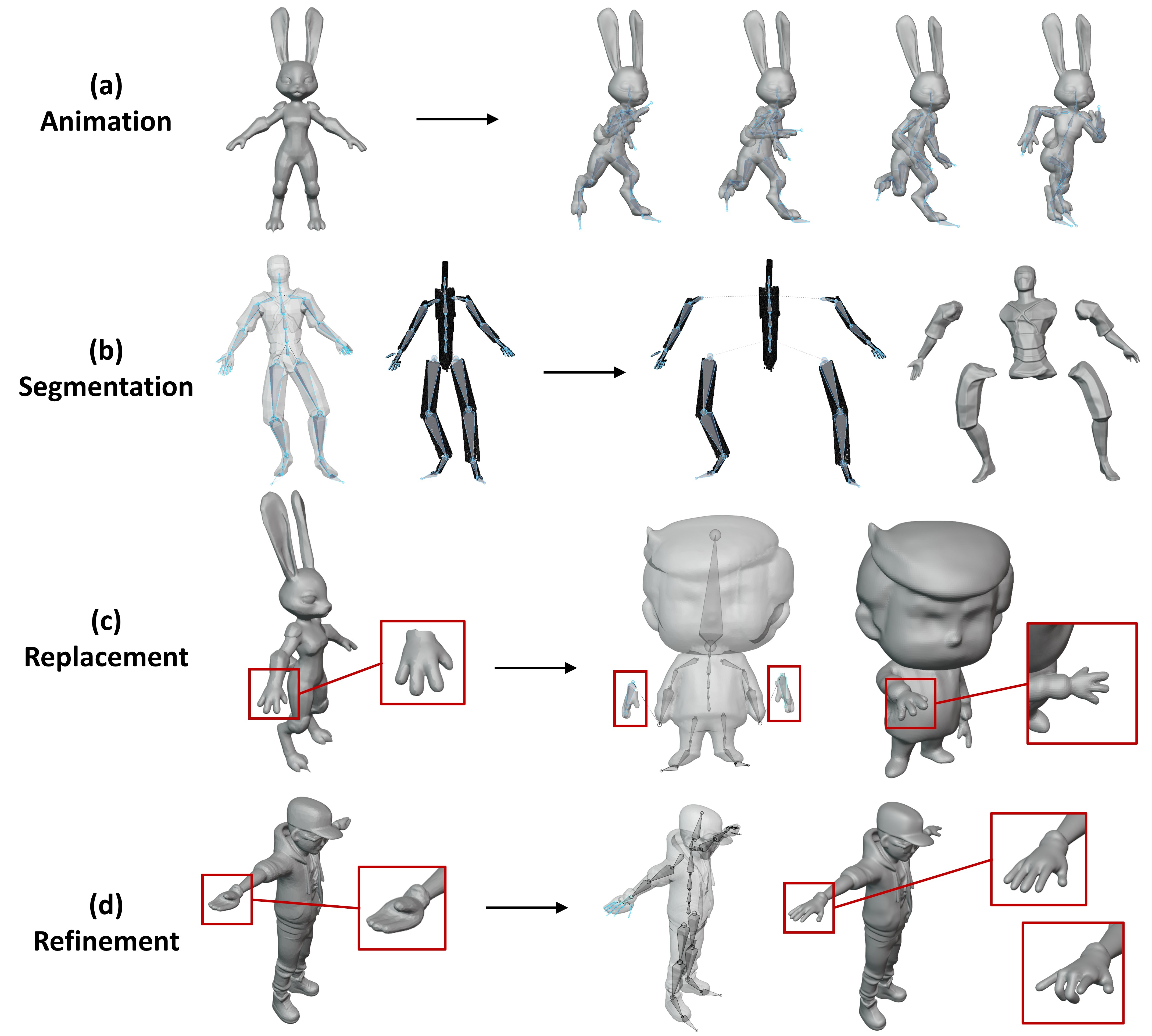
To address these issues, we introduce Make-It-Poseable, a novel feed-forward
framework that reformulates character posing as a skinning-free latent-space transformation problem.
By decoupling shape deformation from the constraints of fixed mesh connectivity, our method directly
operates on compact latent representations to reconstruct characters in target poses.
To achieve this, our framework integrates a latent posing transformer for shape manipulation, a dense pose
representation for fine-grained control, and an adaptive completion module optimized via a
bipartite-matched latent loss to robustly handle topological changes.
Extensive experiments demonstrate that our method significantly outperforms existing baselines in posing
quality. Furthermore, our skeleton-agnostic design exhibits remarkable zero-shot generalization to diverse
morphologies including quadrupeds and seamlessly supports various 3D authoring applications such as part
replacement and refinement.